
Die neue KI von Microsoft kann die Stimme einer Person mit drei Sekunden Ton simulieren

Ars Technica
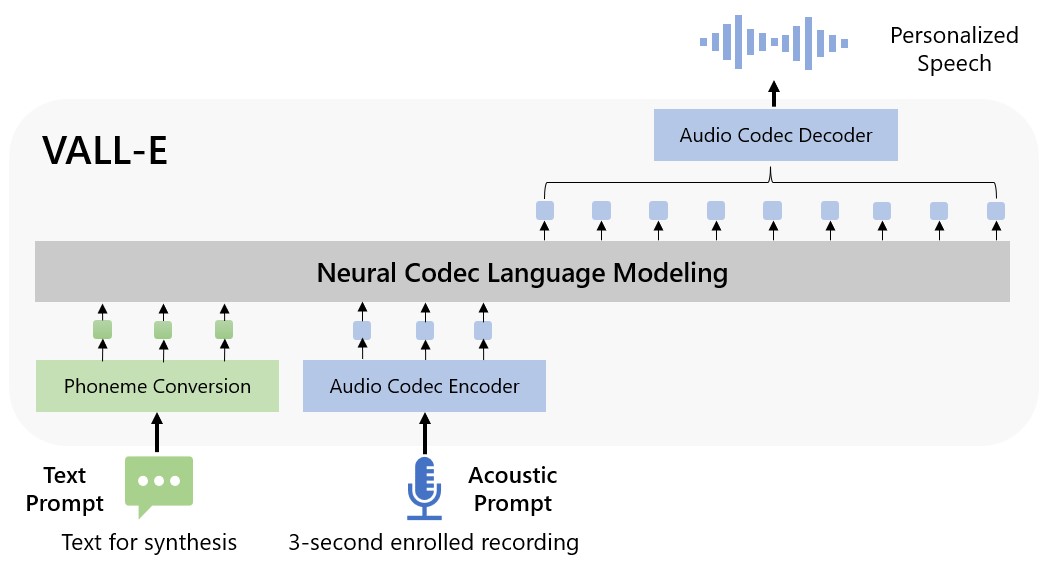
Am Donnerstag kündigten Microsoft-Forscher ein neues Text-to-Speech-Modell für künstliche Intelligenz namens an Tal Es kann die Stimme einer Person genau nachahmen, wenn eine drei Sekunden lange Audioprobe gegeben wird. Sobald es einen bestimmten Ton gelernt hat, kann VALL-E den Ton dieser Person, die irgendetwas sagt, synthetisieren – und zwar auf eine Weise, die versucht, den emotionalen Ton des Sprechers zu bewahren.
Seine Entwickler gehen davon aus, dass VALL-E für hochwertige Text-to-Speech-Anwendungen, Sprachbearbeitung, bei der eine Aufnahme einer Person bearbeitet und von einem Texttranskript geändert werden kann (was sie dazu bringt, etwas zu sagen, was sie ursprünglich nicht gesagt haben), verwendet werden kann. und Erstellung von Audioinhalten in Kombination mit anderen KI-Modellen wie z GPT-3.
Microsoft nennt VALL-E ein „neuronales Codierungssprachenparadigma“, und es basiert auf einer Technologie namens EnCodec. für tot erklärt im Oktober 2022. Im Gegensatz zu anderen Text-to-Speech-Methoden, die normalerweise Sprache durch Verarbeitung von Wellenformen synthetisieren, generiert VALL-E separate phonetische Encoder aus Text- und Sprachansagen. Es analysiert im Grunde, wie sich eine Person anhört, zerlegt diese Informationen dank EnCodec in separate Komponenten (sogenannte „Codes“) und verwendet die Trainingsdaten, um das abzugleichen, was es darüber „weiß“, wie diese Person klingen würde, wenn sie in einer anderen Sprache sprechen würde Phrasen außerhalb des dreisekündigen Samples. Oder wie Microsoft es in a ausdrückt VALL-E-PAPIER:
Für benutzerdefinierte Sprachgruppierung (z. B. Non-Shot-TTS) generiert VALL-E die entsprechenden Sprachcodes modal zu den aufgezeichneten 3-Sekunden-Aufzeichnungssprachcodes und der Sprachansage, die die Sprecher- bzw. Inhaltsinformationen einschränken. Schließlich werden die generierten Audiocodes verwendet, um die endgültige Wellenform mit dem entsprechenden neuronalen Decodierer zu gruppieren.
Microsoft trainierte die Sprachsynthesefähigkeiten von VALL-E in eine von Meta zusammengestellte Klangbibliothek namens Libre Lite. Es enthält 60.000 Stunden Englisch sprechen von mehr als 7.000 Sprechern, größtenteils gezogen aus LibriVox Gemeinfreie Hörbücher. Damit VALL-E gut abschneidet, muss der Ton im Drei-Sekunden-Sample mit einem Ton in den Trainingsdaten übereinstimmen.
auf val-e Website-BeispielMicrosoft stellt Dutzende von Audiobeispielen eines KI-Modells in Aktion bereit. Unter den Beispielen ist ein „Sprecher-Prompt“ ein Drei-Sekunden-Ton, der für VALL-E bereitgestellt wird und nachgeahmt werden muss. Eine „Grundwahrheit“ ist eine bereits vorhandene Aufnahme desselben Sprechers, der eine bestimmte Aussage zu Vergleichszwecken sagt (ähnlich wie eine „Kontrolle“ eines Experiments). „Baseline“ ist ein Synthesebeispiel, das durch das herkömmliche Text-zu-Sprache-Syntheseverfahren bereitgestellt wird, und das „VALL-E“-Beispiel wird vom VALL-E-Modell ausgegeben.
Microsoft
Bei der Verwendung von VALL-E zur Generierung dieser Ergebnisse gaben die Forscher lediglich ein drei Sekunden langes „Speaker Prompt“-Sample und eine Textzeichenfolge (was die Stimme sagen sollte) in VALL-E ein. Vergleichen Sie also die „Ground Truth“-Probe mit der „VALL-E“-Probe. In einigen Fällen liegen die beiden Proben sehr nahe beieinander. Einige der VALL-E-Ergebnisse scheinen computergeneriert zu sein, andere werden jedoch wahrscheinlich mit menschlicher Sprache verwechselt, was das Ziel des Modells ist.
Neben der Beibehaltung des Stimmtimbres und des emotionalen Tons des Sprechers kann VALL-E auch die „akustische Umgebung“ einer Stimmprobe simulieren. Wenn das Sample beispielsweise von einem Telefonanruf stammt, würde die Audioausgabe die akustischen und Frequenzeigenschaften eines Telefonanrufs in seiner synthetisierten Ausgabe simulieren (das ist eine ausgefallene Art zu sagen, dass es auch wie ein Telefonanruf klingen würde). und Microsoft Proben (im Abschnitt „Synthese der Vielfalt“) zeigte, dass VALL-E Variationen in der Tonhöhe erzeugen kann, indem es die zufälligen Startwerte ändert, die im Erzeugungsprozess verwendet werden.
Vielleicht hat Microsoft aufgrund der Fähigkeit von VALL-E, Unfug und Täuschung zu schüren, keinen VALL-E-Code für andere zum Testen bereitgestellt, sodass wir die Fähigkeiten von VALL-E nicht testen konnten. Forscher scheinen sich des potenziellen sozialen Schadens bewusst zu sein, den diese Technologie verursachen könnte. Zum Abschluss des Papiers schrieben sie:
„Da VALL-E Sprache synthetisieren kann, die die Identität des Sprechers bewahrt, kann es potenzielle Risiken beim Missbrauch von Modellen geben, wie z. B. das Spoofing der Spracherkennung oder die Identität eines bestimmten Sprechers. Um diese Risiken zu mindern, ist es möglich, ein Erkennungsmodell zu erstellen unterscheiden, ob ein bestimmter Lautsprecher synthetisiert wurde oder nicht. Soundtrack von VALL-E. Wir werden auch setzen Microsoft-Prinzipien der künstlichen Intelligenz In der Praxis bei der Entwicklung von Modellen.

„Lebenslanger Social-Media-Liebhaber. Fällt oft hin. Schöpfer. Leidenschaftlicher Feinschmecker. Entdecker. Typischer Unruhestifter.“